Parallel_Programming
[toc]
HPC
Parallel Computing
multithreading - How to "multithread" C code - Stack Overflow
You should have a look at openMP for this. The C/C++ example on this page is similar to your code: https://computing.llnl.gov/tutorials/openMP/#SECTIONS
MPI
OpenACC
OpenMP
A.16 Using Locks | Microsoft Docs
// omp_using_locks.c // compile with: /openmp /c #include <stdio.h> #include <omp.h> void work(int); void skip(int); int main() { omp_lock_t lck; int id; omp_init_lock(&lck); #pragma omp parallel shared(lck) private(id) { id = omp_get_thread_num(); omp_set_lock(&lck); printf_s("My thread id is %d.\n", id); // only one thread at a time can execute this printf omp_unset_lock(&lck); while (! omp_test_lock(&lck)) { skip(id); // we do not yet have the lock, // so we must do something else } work(id); // we now have the lock // and can do the work omp_unset_lock(&lck); } omp_destroy_lock(&lck); }
> ```c
> omp_set_dynamic(0);
> omp_set_num_threads(16);
> #pragma omp parallel shared(x, npoints) private(iam, ipoints)
> {
> if (omp_get_num_threads() != 16)
> abort();
> iam = omp_get_thread_num();
> ipoints = npoints/16;
> do_by_16(x, iam, ipoints);
> }
> ```
Irregular OpenMP parallelism - openmp - Stack Overflow
Recursive calculation for pi using OpenMP tasks
The code below calculates the value of PI using a recursive approach. Modify the MAX_PARALLEL_RECURSIVE_LEVEL value to determine at which recursion depth stop creating tasks. With this approach to create parallelism out of recursive applications: the more tasks you create, the more parallel tasks created but also the lesser work per task. So it is convenient to experiment with the application to understand at which level it creating further tasks do not benefit in terms of performance.
#include <stdio.h> #include <omp.h> double pi_r (double h, unsigned depth, unsigned maxdepth, unsigned long long begin, unsigned long long niters) { if (depth < maxdepth) { double area1, area2; // Process first half #pragma omp task shared(area1) area1 = pi_r (h, depth+1, maxdepth, begin, niters/2-1); // Process second half #pragma omp task shared(area2) area2 = pi_r (h, depth+1, maxdepth, begin+niters/2, niters/2); #pragma omp taskwait return area1+area2; } else { unsigned long long i; double area = 0.0; for (i = begin; i <= begin+niters; i++) { double x = h * (i - 0.5); area += (4.0 / (1.0 + x*x)); } return area; } } double pi (unsigned long long niters) { double res; double h = 1.0 / (double) niters; #pragma omp parallel shared(res) { #define MAX_PARALLEL_RECURSIVE_LEVEL 4 #pragma omp single res = pi_r (h, 0, MAX_PARALLEL_RECURSIVE_LEVEL, 1, niters); } return res * h; } int main (int argc, char *argv[]) { #define NITERS (100*1000*1000ULL) printf ("PI (w/%d iters) is %lf\n", NITERS, pi(NITERS)); return 0; }
c++ - How to use lock in openMP? - Stack Overflow
You want the OMP_SET_LOCK/OMP_UNSET_LOCK functions: https://computing.llnl.gov/tutorials/openMP/#OMP_SET_LOCK. Basically:
omp_lock_t writelock; omp_init_lock(&writelock); #pragma omp parallel for for ( i = 0; i < x; i++ ) { // some stuff omp_set_lock(&writelock); // one thread at a time stuff omp_unset_lock(&writelock); // some stuff } omp_destroy_lock(&writelock); Most locking routines such as pthreads semaphores and sysv semaphores work on that sort of logic, although the specific API calls are different.Scoped locking vs. critical in OpenMP - a personal shootout - Thinking ParallelThinking Parallel
> Scoped Locking vs. critical – the comparison
>
> First of all, let’s see what both solutions do:
>
> cannot forget to unset the lock, as it is done automatically for scoped locking or detected as a compile-time error for critical
>
> So the initial problem appears to be solved by both. But wait, there is (unfortunately) more to it. Here are some more reasons to use scoped locking and NOT the critical-directive:
>
> it is allowed to leave the locked region with jumps (e.g. break, continue, return), this is forbidden in regions protected by the critical-directive
> scoped locking is exception safe, critical is not
> all criticals wait for each other, with guard objects you can have as many different locks as you like – named critical sections help a bit, but name must be given at compile-time instead of at run-time like for scoped locking
>
> ***
> The problem with this scenario is that even though the programmer may pass different data into the function, the critical section will prevent the threads from working on them at the same time!
>
> first the example library function:
>
> ```c
> void threadsafe_foo (int& data)
> {
> // do some work
> ...
> #pragma omp critical (threadsafe_foo_1)
> {
> data = rand ();
> }
> }
> ```
>
> And now a piece of code that uses it:
>
> ```c
> int data1, data2;
>
> #pragma omp parallel
> {
> threadsafe_foo (data1);
> // do some work
> threadsafe_foo (data2);
> }
> ```
>
> Even though threadsafe_foo() operates on completely different data, the critical region inside the function does not and cannot know that and therefore the threads are stalling each other unnecessarily.
>
> ```c
> //但我覺得可以用MACRO 來解決
> //例如
> //#define CRITICAL_NAME(X) ##X
> // ...
> // #pragma omp critical (CRITICAL_NAME(variable))
> // this will generate
> // #pragma omp critical (variable)
> //
> ```
>
> ***
> OK, so does this mean that everyone is supposed to forget about the critical directive in OpenMP and use scoped locking? I am afraid it is not that easy, since there are also advantages to using critical:
>
> no need to declare, initialize and destroy a lock
> no need to include, declare and define a guard object yourself, as critical is a part of the language (OpenMP)
> you always have explicit control over where your critical section ends, where the end of the scoped lock is implicit
> works for C and C++ (and FORTRAN)
> less overhead, as the compiler can translate it directly to lock and unlock calls, where it has to construct and destruct an object for scoped locking
>
-
A thread waits at the beginning of a critical region until no other thread is executing a critical region (anywhere in the program) with the same name. All unnamed critical directives map to the same unspecified name.
parallel processing - difference between omp critical and omp single - Stack Overflow
single and critical are two very different things. As you mentioned:
single specifies that a section of code should be executed by single thread (not necessarily the master thread) critical specifies that code is executed by one thread at a time
So the former will be executed only once while the later will be executed as many times as there are of threads.
For example the following code
int a=0, b=0; #pragma omp parallel num_threads(4) { #pragma omp single a++; #pragma omp critical; b++; } printf("single: %d -- critical: %d\n", a, b); will printsingle: 1 -- critical: 4
OpenMP® Forum • View topic - No read/write locks or semaphores?
(I use Linux, gfortran, f90 code, OpenMP2.5)
I have two subroutines. Subroutine A is a search, and any number of threads can be running this at the same time. Subroutine B changes the data that is searched in sub A, and only one thread can be inside subroutine B at any given time. But, when a thread is in subroutine B, no threads can be inside of, or enter, subroutine A. How would one use mutex locks (or another OpenMP feature) to satisfy these requirements? Right now, I have one mutex that covers both subroutines A and B, but this is inefficient because I don't need to serialize subroutine A.
Friends have informed me that pthreads has a read/write lock mechanism (pthread_rwlock_init) that does exactly this. Additionally, the Linux kernel supports semaphores (that can be used to determine how many threads are currently inside subroutine A). But there is nothing in the OpenMP documentation or here on the forum describing this.
Can this be done using the ordinary one-thread lock mechanism in OpenMP, or creative combinations of atomic/critical/lock? Why was this not considered for OpenMP 3.0?
A person smarter than myself said that a read-write lock (and semaphore) can be created using only basic single-thread mutex locks. I'll post code here once I get it to work.
Okay, I did it, and here's the code:
Code: Select all
integer :: numThreads,thisThread,i,numLocks ! create a lot of locks integer(kind=OMP_LOCK_KIND), dimension(16) :: readLock integer(kind=OMP_LOCK_KIND) :: writeLock call omp_init_lock (writeLock) ! enter the parallel region !$omp parallel private(thisThread) thisThread = omp_get_thread_num() + 1 if (thisThread==1) numThreads = omp_get_num_threads() call omp_init_lock (readLock(thisThread)) !$omp barrier !$omp do call omp_set_lock (readLock(thisThread)) ! READ block ************ call omp_unset_lock (readLock(thisThread)) ! other work call omp_set_lock (readLock(thisThread)) ! READ block ************ call omp_unset_lock (readLock(thisThread)) ! other work ! all other writers must wait here call omp_set_lock (writeLock) numLocks = 0 ! stall while waiting to get all read locks do while (numLocks < numThreads) do i=1,numThreads if (omp_test_lock (readLock(i))) numLocks = numLocks+1 enddo enddo ! ah! finally have all read locks ! WRITE block ************ ! release all read locks first do i=1,numThreads call omp_unset_lock (readLock(i)) enddo ! and release the write lock call omp_unset_lock (writeLock) !$omp end do call omp_destroy_lock (readLock(thisThread)) ! leave the parallel region !$omp end parallel call omp_destroy_lock (writeLock)This code replaces a semaphore with an array of locks (make sure to size the array appropriately), and writing can only occur when the writer thread obtains all of the read locks.
c++ - Can I assign multiple threads to a code section in OpenMP? - Stack Overflow
You can do this using nested parallel regions.
omp_set_nested(1); #pragma omp parallel num_threads(2) { if (omp_get_thread_num() == 0){ #pragma omp parallel num_threads(8) { // Task 0 } }else{ #pragma omp parallel num_threads(8) { // Task 1 } } }Alternatively, you could do it like this:
#pragma omp parallel num_threads(16) { if (omp_get_thread_num() < 8){ // Task 0 }else{ // Task 1 } }Note, this code will not work if OpenMP decides to use fewer than 16 threads. You will have to insert your own cleanup code for that.
EDIT: In response to your update:
class some_class{ void task(){ cout<<"Entering the task method"<<endl; #pragma omp parallel for num_threads(8) for(int i=0; i < large_matrix.rows(); i++){ perform_thread_safe_operation(large_matrix.getRow(i)); } } matrix large_matrix; }; void main(){ omp_set_nested(1); //I have 16 cores, so I want to spawn 16 threads some_class o1; some_class o2; #pragma omp parallel num_threads(2) { if (omp_get_thread_num() == 0){ // I want 8 of the 16 threads to execute this line: o1.task(); }else{ // and 8 remaining threads to execute this line: o2.task(); } } }
Parallel theorem
-
Amdahl's Law
定義 : 針對電腦系統裡面某一個特定的元件予以最佳化,對於整體系統有多少的效能改變 例子 : 方法一: 簡單來說就是全部時間都給我算就對了!
整體的speed up也就是效能的提升 要從兩個面向來看

第一個部分是我們有辦法改進的部分 :
從原本開車換成開飛機
第二個部分是我們沒有辦法改進的部分 :
也就是市區的時間 這些通通都必須要同時列入考量 也因此我們會發現實際的speed up只有2.5倍,而並非是飛機比汽車快4倍
方法二: 比率算法 (看時間的比率)

1代表原本你有做任何改善之前的效能(時間) 在市區的行車時間是沒有辦法被改善的 (而它佔整體的行車時間百分之二十 也就是0.2) 至於在高速公路上面的行車時間是有辦法被改善的 我們可以透過換成改搭飛機 而讓原本的效率快了四倍(時間變成1/4) 也因此整體計算完成之後 我們會發現實際上我們的效能提升是2.5倍
來個有趣的假設 (極限大的提升)
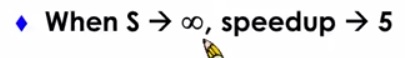
假設飛機的效率是開車的無窮大倍 也就是說飛機可以瞬間從台北到高雄
市區的一個小時依然是沒有辦法被改進的 所以實際上我們我們得到整體效能的提升只有五倍
重要的觀念
如果我們針對系統特定的部分進行效能改變 而想要了解改變了這個部分之後對於整體系統效能的改進是多少 那麼我們需要很清楚的知道 我們改變的部分它 "執行時間佔系統整體執行時間的比率是多少" 同樣的我們 "不能忽略的是我們沒有改變的部分" 也就是沒有加速的部分它的執行時間依然是存在的 依然也會影響到系統整體的執行效能
力氣要花在刀口上
刀口 其實就是我們 改進的這個部分它的執行時間比率佔整體執行時間的比率是多少
如果越高就代表我們的改進對於整體系統的效率提升會比較多 反之 就會比較少 結論 :
我們可以從下面這個式子
1 : 整體時間 F : 可以改變的部分占總時間的比例(時間) S : F/S 改變後時間變成改變前時間F的 1/S 倍
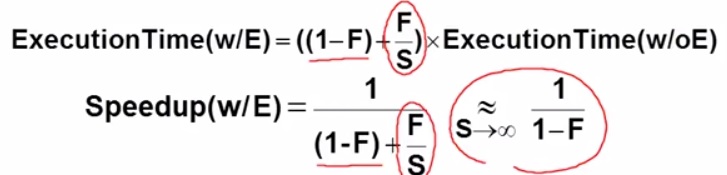
我們不可能無窮盡的只提升系統某一個特定部分的效率
如果我們這麼做,事實上 "最後系統效能的提升是有所極限的"
因為當我們不斷地改進這個系統的某一個特定部分時 這個部分它的執行時間會越來越少 越來越少 以致於即時我們花了更多的力氣 投注在這個部分的效能改進 實際上對於整體的執行時間並沒有太大的幫助